Summary
DevOps OKR examples for site reliability provide a structured framework for engineering teams to balance the speed of software delivery with the stability of production environments. By defining clear Objectives and Key Results, organizations can move beyond simple monitoring to achieve measurable improvements in system uptime, incident response efficiency, and infrastructure automation.
Effective site reliability engineering (SRE) relies on aligning technical metrics with broader business outcomes. Using these examples allows DevOps leads to translate complex system health data into actionable goals that ensure high availability and a seamless user experience for mid-market and enterprise-level platforms.
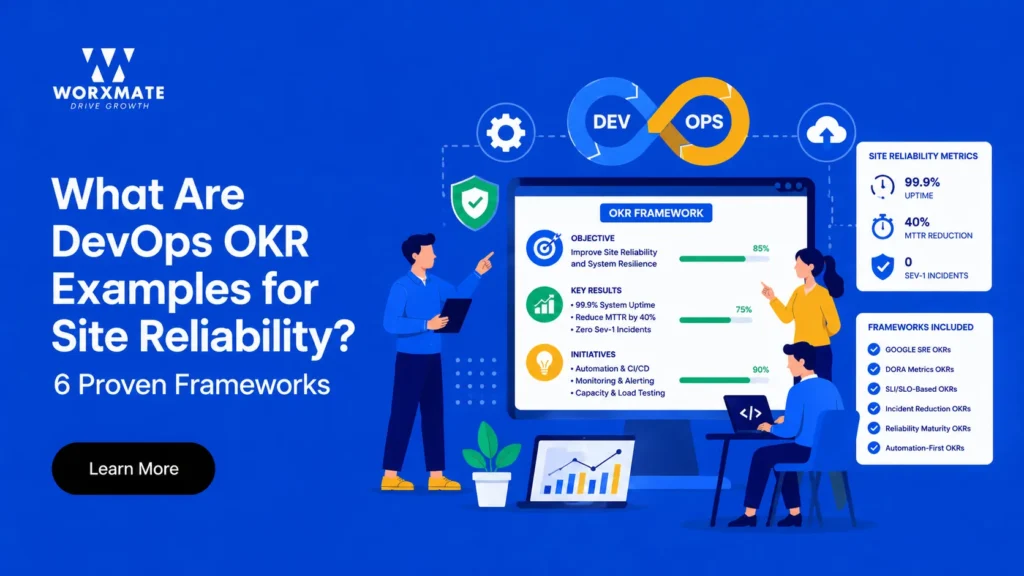
What are DevOps OKR examples for site reliability and how do they bridge the gap between development speed and operational stability? For modern engineering leaders, the challenge is no longer just about shipping code; it is about ensuring that the code performs reliably under varying loads. Site Reliability Engineering, a discipline popularized by Google, treats operations as an engineering problem, and Objectives and Key Results (OKRs) are the primary tool used to manage this complexity.
Implementing DevOps OKR examples for site reliability helps teams move away from reactive “firefighting” toward proactive system hardening. When technical debt accumulates or manual toil increases, reliability suffers. By setting measurable goals, SRE teams can justify the time spent on automation and infrastructure improvements, ensuring that the platform remains resilient even during rapid scaling phases.
In this guide, we will explore specific DevOps OKR examples for site reliability across key domains, including system availability, incident management, and infrastructure automation. We will also examine how to balance feature velocity with error budgets and provide a framework for tracking these metrics within a strategic performance management system.
Why Site Reliability Engineering Needs OKRs
Site Reliability Engineering is inherently data-driven, but data alone does not create alignment. Without a framework like OKRs, SRE teams often find themselves buried in “toil”—repetitive, manual tasks that provide no long-term value. According to Google, SRE teams should aim to spend at least 50% of their time on engineering work that reduces future toil. OKRs provide the necessary air cover for managers to prioritize this engineering work over immediate ticket resolution.
Furthermore, DevOps performance management requires a shared language between developers and operations. Developers are often incentivized by “velocity” (how fast they can ship), while operations are incentivized by “stability” (how little the system breaks). DevOps OKR examples for site reliability serve as a neutral ground where both parties agree on what level of reliability is “good enough,” allowing for faster innovation without compromising the customer experience.
According to Gartner, the average cost of IT downtime is $5,600 per minute, which can exceed $300,000 per hour for many organizations. By using OKRs to focus on reliability, companies like Microsoft and Adobe have successfully reduced the financial impact of outages while maintaining high deployment frequencies.
The Difference Between SRE Metrics and DevOps OKR Examples for Site Reliability
It is a common mistake to confuse Service Level Indicators (SLIs) or Service Level Objectives (SLOs) with OKRs. While they are related, they serve different purposes. SLIs and SLOs are continuous health monitors, whereas DevOps OKR examples for site reliability are time-bound goals aimed at improving those health monitors or the processes behind them.
For instance, an SLO might be “99.9% of requests must succeed.” An OKR, however, would be “Improve system resilience to achieve 99.9% uptime during peak Q4 traffic.” The Key Results would then focus on the specific actions required to reach that state, such as implementing multi-region failover or reducing database latency. This distinction is critical for organizational alignment across the engineering department.
| Term | Definition | Example in DevOps |
|---|---|---|
| SLI (Indicator) | A specific metric used to measure performance. | Request Latency (ms). |
| SLO (Objective) | The target value for an SLI over a period. | 95% of requests < 200ms. |
| SLA (Agreement) | The legal contract for reliability with users. | 99.9% uptime or service credits. |
| OKR | The strategic goal to improve the system. | Reduce tail latency by 20%. |
DevOps OKR Examples for Site Reliability and System Availability
Availability is the cornerstone of SRE. However, aiming for “100% uptime” is usually a mistake because it is prohibitively expensive and slows down innovation. Instead, DevOps OKR examples for site reliability should focus on achieving “meaningful availability”—ensuring the system is up when and where it matters most to the user.
Effective DevOps OKR examples for site reliability in this category might include:
-
Objective: Enhance Global Platform Availability
Key Result 1: Achieve 99.95% uptime across all production clusters in the US and EMEA regions.
Key Result 2: Reduce the number of “Severity 1” outages caused by database lock-ups from 5 to 0.
Key Result 3: Implement automated health checks for 100% of microservices, reducing false-positive alerts by 30%.
By focusing on performance metrics that reflect the user’s reality, teams can ensure their efforts directly impact customer satisfaction. According to Google, 70% of outages are caused by changes in live systems. Therefore, availability OKRs often involve improving the safety of the deployment pipeline itself.
DevOps OKR Examples for Site Reliability in Incident Management
Incidents are inevitable in complex systems. The goal of SRE is not to eliminate incidents entirely but to minimize their impact through superior incident response goals. These DevOps OKR examples for site reliability focus on the “Mean Time” metrics: Mean Time to Detect (MTTD) and Mean Time to Recovery (MTTR).
According to Harvard Business Review, high-performing DevOps teams have a 24x faster MTTR compared to low-performing peers. To join the ranks of high performers, consider these DevOps OKR examples for site reliability:
-
Objective: Optimize Incident Response Efficiency
Key Result 1: Reduce Mean Time to Recovery (MTTR) for customer-facing outages from 45 minutes to under 15 minutes.
Key Result 2: Automate incident bridge creation and stakeholder notification for 100% of P1 incidents.
Key Result 3: Conduct 100% of post-mortem reviews within 48 hours of incident resolution, with at least 2 actionable items identified per report.
Using actionable goals for incident management ensures that the team is learning from every failure. This iterative process is essential for building a culture of continuous improvement within the engineering organization.
Unlock Goal Clarity and Accelerate Employee Growth
Looking to drive goal clarity and employee growth? Discover how Worxmate’s AI-powered Performance Management Software can help.
Infrastructure Automation and Scalability OKRs
Scale is the ultimate test of site reliability. Manual infrastructure management cannot keep pace with modern cloud-native environments. Therefore, infrastructure automation OKRs are vital for reducing operational overhead and ensuring consistency across environments. These DevOps OKR examples for site reliability focus on “Infrastructure as Code” (IaC) and self-healing capabilities.
-
Objective: Transition to a Fully Automated Infrastructure
Key Result 1: Migrate 90% of legacy infrastructure components to Terraform or CloudFormation templates.
Key Result 2: Implement auto-scaling policies that reduce manual intervention during traffic spikes by 50%.
Key Result 3: Reduce the time required to spin up a new production-ready environment from 3 days to under 2 hours.
Integrating these DevOps OKR examples for site reliability into your OKRs for AI-driven teams or cloud engineering squads ensures that scalability is built-in, not bolted on. Automation not only improves reliability but also frees up senior engineers to focus on higher-value architectural work.
Balancing Feature Velocity with Error Budgets
One of the most powerful concepts in SRE is the “Error Budget.” An error budget is the amount of downtime or errors a service can tolerate before it violates its SLO. DevOps OKR examples for site reliability often use the error budget as a “governor” for feature releases. If the budget is exhausted, feature releases are paused, and all engineering effort shifts to reliability work.
Consider these error budget examples as part of your OKR planning:
-
Objective: Maintain a Healthy Balance Between Innovation and Stability
Key Result 1: Ensure that no more than 80% of the quarterly error budget is consumed by planned releases.
Key Result 2: Implement a “freeze” policy that triggers automatically when the error budget hits 95% consumption.
Key Result 3: Dedicate 20% of every sprint to “reliability debt” tasks whenever the error budget burn rate exceeds 1.5x the target.
This approach aligns with the Objectives and Key Results philosophy by creating a clear trade-off mechanism. It prevents the friction between product managers and SREs by providing a data-backed reason to slow down or speed up.
Best Practices for Tracking SRE OKRs in Worxmate
Tracking DevOps OKR examples for site reliability requires a tool that can integrate with your existing technical stack. Spreadsheets are often too static to capture the dynamic nature of SRE metrics. Using real-time performance dashboards within Worxmate allows teams to see exactly how their daily engineering tasks contribute to long-term reliability goals.
When setting up your SRE OKRs, ensure that you are tracking metrics that really matter. Avoid vanity metrics like “number of lines of code written” and focus on outcomes like “percentage of manual tasks automated.” Worxmate’s platform enables you to link these technical KRs to broader company objectives, providing the visibility that CTOs and Engineering Directors need to justify infrastructure investments.
By implementing these DevOps OKR examples for site reliability, organizations can move toward a more resilient, scalable, and automated future. Whether you are managing a small startup or a massive enterprise cloud, the discipline of setting and tracking reliability OKRs is the key to sustained technical excellence.
Ready to accelerate your site reliability journey? Start your free trial with Worxmate today and discover how our Performance Management software can transform your strategy into measurable results.